
Antes de falar sobre AWS Lambda SnapStart, vale recapitular que a explosão de serviços na nuvem nas últimas décadas nos levou a uma era repleta de tecnologias e facilidades anteriormente inimagináveis. Hoje, podemos desenvolver e disponibilizar aplicações sem nos preocuparmos com infraestrutura física.
Através de um único clique, é possível contratar serviços virtuais, alugar servidores e bancos de dados, além de escalar nossos recursos automaticamente e armazenar arquivos com capacidade praticamente ilimitada.
Essa mudança também nos permite deixar de lado as preocupações com servidores e focar exclusivamente na lógica de negócio, graças a plataformas de computação sem servidor, como o AWS Lambda da Amazon Web Services (AWS), que será o foco deste artigo.
AWS Lambda e seu potencial
Desde o seu lançamento em 2014, inicialmente suportando apenas Python e Node.js, o AWS Lambda tem entusiasmado a comunidade e conquistado seu espaço. Ao longo do tempo, o serviço evoluiu consideravelmente, expandindo sua capacidade de execução e integração com outros serviços, além de obter melhorias significativas em desempenho e escalabilidade.
Atualmente, a Lambda suporta várias linguagens de programação. No entanto, ainda não existe um consenso sobre o uso do Java para projetos nesta plataforma.

Evolução da Lambda de 2014 a 2023.
Indicamos também que você confira o vídeo “Arquitetura Serverless: AWS Lambda” para acompanhar mais sobre o tema. Assista!
Explorando a integração entre Java e AWS Lambda
O suporte ao Java foi adicionado ao AWS Lambda em 2016, mas é comum encontrar opiniões de que o Java, quando utilizado com a Lambda, apresenta um desempenho inferior em comparação com outras linguagens.
Essa opinião é baseada no tempo de inicialização da Máquina Virtual Java (JVM), que resulta em um tempo de inicialização maior da Lambda. Como esse não é um servidor que fica constantemente ligado, essa inicialização afeta diretamente a disponibilidade da aplicação. Esse cenário se torna mais desafiador quando frameworks como o Spring são utilizados, pois aumentam ainda mais o tempo de carregamento da aplicação.
No entanto, é importante não considerar essa opinião como uma verdade absoluta, pois o serviço continua evoluindo e atualmente apresenta soluções inovadoras para esse problema. Prepare-se para explorar o conceito revolucionário do SnapStart e descobrir como ele supera a grande desvantagem do Java em relação a outras linguagens de programação.
Será que esse avanço tecnológico finalmente põe fim a esse dilema e oferece às pessoas desenvolvedoras uma nova e empolgante opção para enriquecer seu amplo portfólio de tecnologias? Acompanhe a gente nesta jornada para descobrir e desvendar os segredos do AWS Lambda SnapStart. Boa leitura!
Compreendendo o conceito do AWS Lambda SnapStart
Como o AWS Lambda SnapStart funciona em detalhes
No final de 2022, o AWS Lambda SnapStart foi anunciado pela AWS como uma otimização para funções Java. Segundo a empresa, essa otimização oferece um desempenho de inicialização até dez vezes mais rápido, sem nenhum custo adicional. Apesar dos benefícios significativos, a utilização do SnapStart é bastante simples, exigindo apenas a ativação de uma opção de configuração adicional na função Lambda.
Vamos agora explorar os detalhes de como o AWS Lambda SnapStart funciona. Para isso, é importante compreender o ciclo de vida de uma função Lambda:
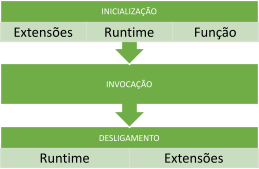
Ciclo de vida da função Lambda comum.
Quando uma função é acionada, ela passa por três fases: inicialização, invocação e desligamento. No caso do Java, a fase de inicialização é onde surge um desafio, pois a JVM precisa ser iniciada e, em seguida, carregar a aplicação.
Se um framework como o Spring é utilizado no projeto, o tempo de inicialização é ainda maior devido ao tempo necessário para inicializar o framework. Essa situação não é ideal para aplicações que exigem baixa latência.
Agora, vamos examinar o que acontece quando uma função Lambda é otimizada com o SnapStart:
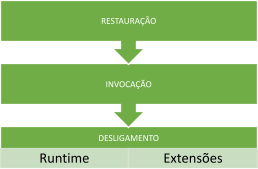
Ciclo de vida de uma função Lambda com SnapStart.
A fase de inicialização é substituída pela fase de restauração, enquanto o restante do ciclo de vida permanece o mesmo. Isso ocorre porque, quando uma função é publicada com o SnapStart ativado, a AWS realiza uma pré-inicialização da função e armazena em cache o estado de memória dessa aplicação já inicializada.
Dessa forma, quando a Lambda é acionada, a fase de inicialização não é necessária. Basta restaurar a memória armazenada em cache e, em seguida, invocar a função normalmente.
Devido ao tempo de restauração ser significativamente menor do que o tempo de inicialização, essa otimização torna o Java novamente uma linguagem competitiva em termos de tempo de inicialização na Lambda, desmistificando seu uso para aplicações que exigem velocidade.
Limitações e compatibilidade do AWS Lambda SnapStart
Ao optar por ativar o recurso do AWS Lambda SnapStart, é importante estar ciente de algumas limitações específicas impostas pela AWS. Essas limitações incluem:
- Linguagem: o SnapStart é exclusivo para o uso com funções Lambda desenvolvidas em Java. Portanto, não é possível ativá-lo ao desenvolver uma Lambda em outra linguagem de programação.
- Memória: enquanto uma função Lambda permite provisionar qualquer valor de memória entre 128 MB e 10.240 MB, ao usar o SnapStart, o valor máximo disponível é limitado a 512 MB.
- Arquitetura: o SnapStart não suporta simultaneidade provisionada, ambientes “arm64” e nem o serviço Amazon Elastic File System (Amazon EFS).
Além disso, é necessário observar algumas considerações de compatibilidade:
- Unicidade: se o código da sua aplicação precisa gerar informações únicas para cada execução da Lambda, como um ID de execução, tome cuidado para não executar esse código durante a fase de inicialização. Isso ocorre porque um snapshot da aplicação é criado após a inicialização, e qualquer objeto aleatoriamente montado nessa fase será reutilizado em todas as execuções, perdendo seu estado único.
- Conexões de rede: se a sua aplicação estabelece conexões com outros servidores ou com um banco de dados durante a inicialização, essas conexões podem não estar mais ativas quando a Lambda restaurar um snapshot. É importante garantir que a sua aplicação seja capaz de reestabelecer essas conexões quando for invocada.
Essas limitações e considerações de compatibilidade devem ser levadas em conta ao decidir pela ativação do AWS Lambda SnapStart em seu projeto.
Decidindo entre o uso do SnapStart ou Simultaneidade Provisionada
Ao decidir entre o uso do SnapStart e a simultaneidade provisionada, é essencial considerar suas necessidades específicas. A simultaneidade provisionada já era uma opção de otimização para tratar o problema de inicialização da Lambda. Com essa abordagem, a Lambda é mantida sempre ativa para responder imediatamente às solicitações, mas há um custo adicional associado a isso.
Portanto, se sua aplicação exige uma latência ainda menor, abaixo de 100 milissegundos, e você tem disposição de arcar com os custos extras, a simultaneidade provisionada pode ser a melhor opção. No entanto, se seus requisitos suportam uma inicialização em torno de 500 milissegundos, o SnapStart é uma escolha mais adequada, pois não implica custo adicional.
Agora que entendemos o conceito do AWS Lambda SnapStart e suas limitações, vamos prosseguir para um exemplo prático para demonstrar seu funcionamento.
Exemplo prático
Implementando um projeto Java
Para ilustrar o uso do AWS Lambda SnapStart com Java, vamos criar uma função Lambda utilizando o framework Spring Boot 3 e o Maven como gerenciador de dependências.
Começaremos configurando o arquivo pom.xml. Adicione as seguintes configurações:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.6</version>
<relativePath/>
</parent>
E também as dependências a seguir:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-adapter-aws</artifactId>
<version>2022.0.2</version>
</dependency>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-core</artifactId>
<version>1.2.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>io.github.crac</groupId>
<artifactId>org-crac</artifactId>
<version>0.1.3</version>
</dependency>Essas dependências são essenciais para trabalhar com o framework Spring e a execução da função Lambda em Java. Além disso, vamos precisar de uma biblioteca que forneça os ganchos de execução necessários para o SnapStart, a Coordinated Restore at Checkpoint (CRaC).
A seguir, precisamos configurar os plugins no arquivo pom.xml para que o aplicativo seja compilado em um único arquivo JAR executável, que inclua todas as dependências:
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>3.0.6</version>
<dependencies>
<dependency>
<groupId>org.springframework.boot.experimental</groupId>
<artifactId>spring-boot-thin-layout</artifactId>
<version>1.0.29.RELEASE</version>
</dependency>
</dependencies>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.4.1</version>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>aws</shadedClassifierName>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>Essa configuração garante que a Lambda seja empacotada em um único arquivo JAR executável, juntamente com todas as dependências necessárias.
Agora, vamos criar a classe principal do projeto. Ela seguirá o padrão comum de um projeto Spring Boot:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}Essa classe é responsável por iniciar o Spring Boot e executar a função Lambda.
Além da classe principal, precisamos declarar um bean para ser o handler da nossa Lambda. Para manter as responsabilidades separadas, criaremos uma classe de configuração:
@Configuration
public class LambdaHandler {
@Bean
public Function<Request, Response> myLambdaHandler() {
return request -> {
System.out.println(request.getMensagem());
return new Response(HttpStatus.OK, "Sucesso.");
};
}
}O bean myLambdaHandler implementa a lógica da função Lambda. Nesse exemplo, ele imprime a mensagem recebida e retorna uma mensagem de sucesso. Essa é a função de partida da sua Lambda, onde você pode colocar toda a lógica de programação necessária. Lembre-se de retornar o resultado para que a AWS possa interpretar o resultado do processamento.
Essa configuração básica é suficiente para o projeto. No entanto, há uma configuração opcional que podemos abordar. Observe o código a seguir:
@Component
public class SnapshotHook implements Resource {
@PostConstruct
private void init() {
Core.getGlobalContext().register(this);
}
@Override
public void beforeCheckpoint(Context<? extends Resource> context) throws Exception {
// Faça algo
}
@Override
public void afterRestore(Context<? extends Resource> context) throws Exception {
// Faça algo
}
}A classe SnapshotHook implementa a API Coordinated Restore at Checkpoint (CRaC), que é usada pela AWS para disponibilizar os ganchos mencionados acima. O método beforeCheckpoint é invocado após a inicialização da aplicação, mas antes de criar o snapshot da Lambda.
Esse código será executado apenas uma vez para cada versão da Lambda. Já o método afterRestore é executado todas as vezes em que o snapshot é restaurado. É nesse momento que você pode validar e reestabelecer conexões externas, como a bancos de dados. Lembre-se de lidar com possíveis desconexões quando um snapshot é restaurado.
Embora não seja obrigatório implementar essa interface, ao fazer isso, você consegue resolver alguns problemas de compatibilidade do SnapStart.
Isso conclui a primeira parte do exemplo prático. Continuaremos agora com a segunda parte, onde vamos configurar nossa função Lambda.
Configuração adequada da função Lambda no AWS Console
Na segunda parte, vamos configurar a função Lambda para utilizar o SnapStart no Console da AWS. Também é importante configurar corretamente o manipulador da função, considerando o uso do Spring Boot.
Neste exemplo, vamos fazer a configuração da Lambda usando o próprio Console da AWS, entretanto, todas as configurações vistas a seguir podem ser feitas também pelo AWS CLI ou por algum IaaC, como Cloudformation ou Terraform, mas esta abordagem não entrará no escopo deste artigo.
No Console da AWS, ao criar a função Lambda, selecione a linguagem Java 11 ou Java 17 – SnapStart não é suportado no runtime Java 8. Além disso, escolha a arquitetura x86_64, pois o arm64 não é compatível com o SnapStart.
Defina o manipulador da função como org.springframework.cloud.function.adapter.aws.FunctionInvoker. Essa classe será responsável por receber o evento da AWS e direcioná-lo para a função definida na classe LambdaHandler anteriormente.
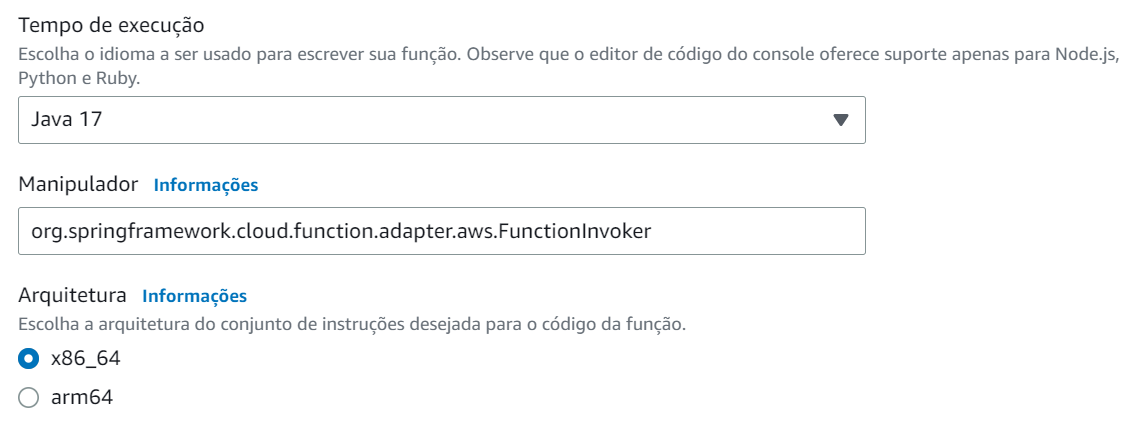
Console da AWS, Configurações de Tempo de Execução da Lambda.
Nas configurações básicas, escolha a opção PublishedVersions no campo SnapStart. Essa é a única configuração disponível, além de none, que desabilita o SnapStart. Em seguida, faça upload do seu arquivo JAR e publique a função Lambda.

Console da AWS, Configurações Básicas da Lambda.
Testes e comparação de desempenho do SnapStart
Agora podemos testar a função Lambda e avaliar o desempenho do SnapStart. No Console da AWS, você pode clicar na aba “Testar” e enviar um evento para realizar um teste rápido.
Realizamos um comparativo entre os dois cenários. Executamos uma função Lambda em Java sem o SnapStart e, em seguida, executamos a mesma função com o SnapStart ativado. Os resultados são mostrados nas figuras a seguir:
No cenário padrão, a Lambda, que utiliza o Spring Boot, levou pouco mais de 6.613 segundos para ser inicializada e mais 2.3 segundos para executar sua tarefa.

Tempo de Inicialização de uma Lambda em Java sem SnapStart.
Com o SnapStart ativado, a Lambda ainda leva 2 segundos para executar sua tarefa, mas a inicialização foi significativamente mais rápida, levando apenas 844 milissegundos para restaurar o snapshot.

Tempo de Restauração de uma Lambda em Java com SnapStart.
Conclusão: Benefícios e considerações finais
Neste artigo, exploramos a otimização SnapStart fornecida pela AWS para Lambdas em Java, que traz uma redução significativa no tempo de inicialização da função Lambda sem custo adicional. Essa otimização coloca o Java em uma posição competitiva em relação a outras linguagens, eliminando a percepção equivocada de que o Java é lento em ambientes sem servidor.
Aprendemos a utilizar o Spring para criar um projeto Java pronto para funções Lambda e implementamos a interface CRaC para resolver possíveis problemas de compatibilidade com o SnapStart. Também aprendemos como configurar uma função Lambda para ativar o SnapStart, realizamos testes e comparamos os resultados em ambos os cenários, com e sem a otimização ativada.
Além disso, observamos uma redução real no tempo de inicialização da Lambda, confirmando a eficácia do SnapStart.
Com este artigo, esperamos ter destacado as vantagens de utilizar o Java em funções Lambda, considerando que o antigo gargalo de desempenho dessa linguagem foi superado. Agora podemos aproveitar as vantagens de uma linguagem com uma grande comunidade e uma ampla variedade de bibliotecas e frameworks em um ambiente sem servidor.
Ficaríamos gratos se você compartilhasse sua opinião sobre este artigo e deixasse sugestões para futuros tópicos. Se desejar aprofundar-se ainda mais nesse assunto, recomendamos a leitura das referências a seguir. Desejamos ótimos estudos!
Referências



