

Lidar com banco de dados é um dos maiores desafios dentro de uma arquitetura de software, pois além de escolher um dentre diversas opções no mercado, é preciso considerar as integrações de persistência de uma aplicação. O objetivo deste artigo é mostrar um pouco desses padrões e conhecer uma nova proposta de especificação, o Jakarta Data, que tem o intuito de facilitar a vida de quem desenvolve com Java.
Entendendo as camadas que podem compor um software
Sempre que falamos sobre complexidade em um sistema corporativo, focamos na antiga estratégia militar romana: dividir e conquistar ou divide et impera, na qual para simplificar o todo, quebramos ele em pequenas unidades.
No mundo do software, uma das maneiras de simplificar e quebrar a complexidade é através de camadas, sejam elas físicas ou lógicas. Essas camadas, principalmente as lógicas, podem ser fragmentadas entre si, tornando-se componentes e/ou funcionalidades.
Esse movimento de quebrar camadas, inclusive, é um dos temas no livro Clean Architecture ao mencionar, por exemplo, a estratégia de separar o código de negócio com o de infraestrutura.
Os 3 tipos de camadas em uma aplicação
Indiferente do estilo arquitetural com o qual você esteja trabalhando, como monólito ou microsserviços, existe um número mínimo de 3 tipos de camadas em uma aplicação, de acordo com o livro Learning Domain-Driven Design. São elas:
- Presentation Layer (camada de apresentação): é a camada de interação com o usuário consumidor desse recurso, seja um usuário final ou alguém que atue na engenharia de software.
- Business Logic Layer (camada de negócio): como o próprio nome sugere, é onde ficará a lógica de negócio, ou nas palavras de Eric Evans, “é a camada que encontra o coração do negócio“.
- Data Access Layer (camada de acesso a dados): é a camada que mantém todo o mecanismo de persistência. No contexto de arquitetura Stateless, podemos pensar que é o local com alguma garantia de estado, salientando que o mecanismo de armazenamento é transparente, seja ele um banco de dados NoSQL, SQL, uma API Rest, etc.
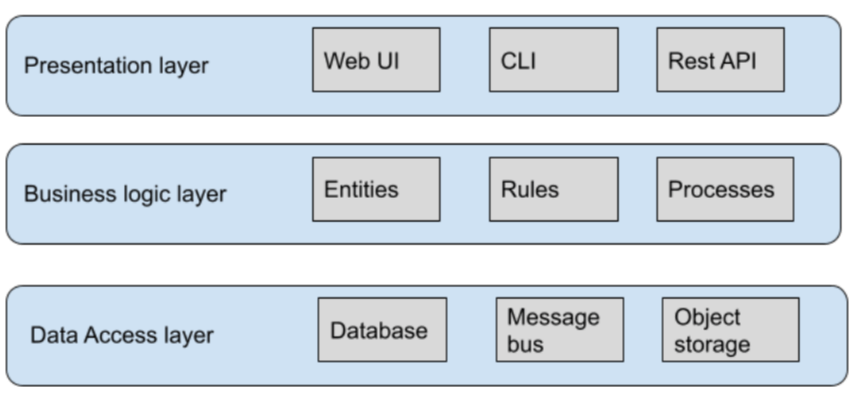
Estes três tipos de camadas tendem a estar presentes na grande variedade de estilos de arquitetura de software, desde as simples, como o MVC, até mesmo as mais complexas, tal como CQRS, modelo hexagonal, onion, dentre outras.
Além dos três tipos de camadas, os modelos arquiteturais se preocupam bastante com a comunicação entre esses componentes para garantir a alta coesão e o baixo acoplamento, além de seguir o princípio de injeção de dependência, o DIP.
Este isolamento da camada de acesso a dados garante, principalmente, que o paradigma do banco de dados “vaze” para dentro do modelo de negócios. Sabemos que existe uma grande diferença – também conhecida como impedância -, em especial entre banco de dados relacionais e a programação orientada a objetos.
Camada de persistência
Realizada a devida introdução sobre camadas e da sua importância, focaremos na camada de persistência ou banco de dados. Um ponto de crítica e de admiração dentro do Paradigma de Orientação a Objeto é que existe uma grande gama de opções e padrões para comunicação.
Para este artigo, falaremos sobre alguns padrões levando em consideração o princípio de responsabilidade única e também o acoplamento com o banco de dados da camada de negócio.
Vale salientar que não existe uma solução “bala de prata”, por isso é importante ter atenção em qual contexto esse padrão será utilizado.
Tipos de padrão quando o assunto é banco de dados
Certamente, temos diversos modelos de integração e padrões entre o banco de dados e OOP. Este artigo foca nos seguintes:
- Padrão 1: Data-Oriented programming
- Padrão 2: Active Record
- Padrão 3: Mapper
A seguir, vamos ver esses padrões em detalhes.
Padrão 1: Data-Oriented programming
Em seu livro Data-Oriented, o autor Yehonathan Sharvit traz como proposta uma redução de complexidade promovendo e tratando os dados como “cidadão de primeira classe”.
Este padrão se resumo em três princípios:
- O código é separado por dados.
- Os dados são imutáveis.
- Os dados têm acesso flexível.
Essa proposta elimina a camada de entidades, focando explicitamente nos dicionários de dados através, por exemplo, de uma implementação de Map.
Padrão 2: Active Record
Esse padrão se tornou bastante popular depois do livro “Patterns of Enterprise Application Architecture” do Martin Follower.
De forma resumida, o padrão tem um único objeto, que é responsável tanto pelos dados quanto pelo comportamento. Isso permite simplificar as regras de negócio, uma vez que a ideia é que haja o acesso direto aos dados.
Contudo, no caso de arquiteturas mais complexas, o Active Record tende a se tornar bem difícil de lidar, já que adicionamos um alto acoplamento entre a solução de banco de dados sem falar na quebra de responsabilidade única. Ou seja: além de responsável pelas regras de negócio, a mesma classe fica também responsável pelas operações do banco de dados.
Dentro do mundo Java, a solução mais recente e que vem sendo amplamente utilizada é o Panache do Quarkus. Dessa forma, é possível realizar uma aplicação com microsserviços com apenas duas classes.
<pre=java>
@Entity
public class Person extends PanacheEntity {
public String name;
public LocalDate birth;
public Status status;
}
Person person =...;
// persist it
person.persist();
ist<Person> people = Person.listAll();
// finding a specific person by ID
person = Person.findById(personId);
</pre>Exemplo de trecho de código Panache e Quarkus extraído da documentação oficial.
Padrão 3: Mapper
Outra solução de comunicação entre banco de dados que vai ao encontro à premissa anterior é o Mapper. De modo geral, ele deixa separados a entidade e as operações de banco de dados, o que, no máximo, tende a aparecer dentro das classes são os metadados ou anotações do mundo Java.
Este padrão garante uma maior separação entre a camada de negócio e do banco de dados, além de garantir o Princípio de Responsabilidade Única. Com isso, simplificamos a manutenção e a leitura em aplicações, já que temos uma classe para a entidade e outra para operações de banco de dados.
Porém, para projetos simples, o Mapper tende a ser inviável. É o caso, por exemplo, de aplicações extremamente simples e com CRUD que, a depender do estilo, precisará de três ou quatro classes para alcançar o mesmo objetivo, ao contrário de padrões como Active Record, que realizaria esta função com metade do número de objetos.
O exemplo mais comum, certamente, é o ORM Hibernate. Porém, esse tipo de solução não é exclusividade para os bancos de dados relacionais, pois existem soluções para os NoSQL como o Spring Data e o Jakarta NoSQL.
<pre=”java”>
@Entity
public class Person {
@Id
String name;
@Column
LocalDate birth;
@Column
Status status;
}
Person person =...;
template.insert(person);
List<Person> people = template.query("select * from Person");
// finding a specific person by ID
person = template.find(Person.class, personId);
</pre>Exemplo de trecho de código utilizando o Jakarta NoSQL.
Padrões DAO versus Repository
A partir de um Mapper, é possível pensar em mais dois padrões. São eles:
- DAO (Data Access Object)
- Repository
Estes padrões levam em consideração o desacoplamento entre o modelo e a camada de persistência, mas a semelhança acaba por aí.
As diferenças estão no acoplamento por estar ligado à camada de acesso aos dados, e não ao modelo, além do foco nas camadas de serviços, na semântica e na nomenclatura. Vamos entender melhor esses modelos separadamente:
Data Access Object (DAO)
O padrão Data Access Object (DAO) isola as camadas de aplicação e negócio da persistência por meio de uma API de abstração. Esta API, por sua vez, traz uma semelhança próxima ao mecanismo do banco de dados.
<pre=”java>
Person person =...;
personDAO.insert(person);
// finding a specific person by ID
person = personDAO.read(id);
</pre>Exemplo de trecho de código com operação de API a partir do padrão DAO.
Repository
O padrão Repository (Repositório) é um mecanismo que permite encapsular o comportamento de armazenamento, recuperação e pesquisa, emulando uma coleção de objetos. Dessa forma, o padrão esconde ainda mais a relação do mecanismo de persistência.
Este padrão foca na maior proximidade das entidades e esconde de onde os dados vêm, o que possibilita um Repository utilizar um padrão DAO em si.
Resumindo DAO x Repository
Um ponto importante é a semântica. Vamos dar um exemplo: considerando que uma entidade Carro teria como classe Garagem, que representa a coleção das entidades. O resultado seria o do trecho de código a seguir:
<pre=”java>
Car car =...;
garage.save(car);
// finding a specific car by ID
car = garage.get(id);
</pre>
Exemplo de trecho de código com uma aplicação que utiliza o padrão Repository.
Em resumo: se compararmos os dois tipos de padrão dentro do Mapper:
- O DAO foca em uma abstração para acesso a algum tipo de dados.
- O Repository foca em uma coleção, não importando a origem do objeto. Por esse motivo, é possível que um Repository utilize um DAO para alcançar o seu objetivo.
Nasce uma nova proposta de API para acesso a dados: Jakarta Data
Depois de conhecer todos os padrões, e suas respectivas importâncias e trade-offs, é importante darmos mais um passo: o de conhecer uma API que explore melhor esses padrões e, assim, facilite a adoção de boas práticas com Java e recursos de dados.
É aí que nasce a proposta de uma nova especificação chamada Jakarta Data. Conheça mais sobre ela aqui (Google Documentos).
O Jakarta Data traz como premissa três princípios:
- Uma API fácil e declarativa.
- Uma coesão nessa camada.
- Um desacoplamento das outras camadas.
Ainda em sua primeira versão, o foco desta nova proposta está na entrega do padrão Repository de modo que, com apenas uma interface e algumas anotações, seja possível implementar o Jakarta Data, inicialmente, em três projetos: Relacionais com JPA, NoSQL com Jakarta NoSQL e Rest com Rest Client for MicroProfile.
<pre=”java”>
@Entity
public class Person {
@Id
String name;
@Column
LocalDate birth;
@Column
Status status;
}
public interface PersonRepository extends Repository<Person, String> {
}
Person person =...;
repository.save(person);
Optional<Person> person = repository.findById(id);
repository.deleteById(id);
</pre>Exemplo de trecho de código que mostra uma inicial da interface do padrão Repository do qual o cliente não saberá a origem dos dados, pois essa questão se torna responsabilidade de cada vendor.
Em resumo: a partir do Jakarta Data, é mais fácil lidar com a camada de negócio tanto em relação à persistência poliglota quanto com o seu desacoplamento.

Jakarta Data: mais facilidade e integração
De fato, trabalhar com Orientação a Objetos e Persistência traz, em si, bastante complexidade por sua riqueza de opções, indiferente da sua origem.
No geral, sempre levamos em conta o grau de isolamento das outras camadas, além da sua facilidade de uso e manutenção. Deste cenário, nasceu o Jakarta Data, cujo objetivo é auxiliar o uso desses padrões de um modo simples e integrado ao mundo de especificação Java. E, como padrão, a expectativa é o total suporte da comunidade, auxiliando e dando feedback.
Gostou de conhecer mais sobre o Jakarta Data? Então deixe suas impressões nos comentários!



