

A adoção de Machine Learning Operations (MLOps), termo que vem sendo usado para descrever técnicas e boas práticas de sistemas de machine learning em produção, vem crescendo muito nos últimos anos.
Existem muitas novidades e pesquisas em destaque, mas outros dados são preocupantes: quase 90% dos projetos de machine learning falharam e algumas empresas nunca implantaram um modelo como esse em produção.
Dito isso, resolvi escrever um post para ajudar empresas com pouca maturidade a implementar MLOps inicial.
Vale ressaltar que trataremos MLOps como um paradigma que combina um conjunto técnico e processos, por meio de um guia para uma arquitetura mínima, simples, segura e escalável.
Princípios de MLOps
Por ser um termo de uma cultura recente, o MLOps carrega princípios, sendo eles práticas e processos básicos que foram estabelecidos por grandes empresas de tecnologia e que são usados amplamente em Big Techs (por exemplo, Google, Apple, Facebook, etc.) e empresas com forte maturidade em MLOps.
Por que digo Big Techs? Porque são as mais avançadas em MLOps na indústria atualmente (você vai conferir nas referências alguns artigos sobre isso), as primeiras a explorar e falhar nessa disciplina.
Na maior parte deste artigo, você vai conhecer ferramentas e práticas aplicadas por essas empresas, que influenciam a maioria das soluções. Vamos lá?
Tecnologias
O primeiro princípio que veremos sobre a área de MLOps é composto por três outras disciplinas de tecnologia já conhecidas:
- engenharia de dados;
- aprendizado de máquina (Machine Learning);
- DevOps;
Você pode observar que o MLOps é uma interseção entre disciplinas presentes em tecnologia.
Começamos com a engenharia de dados, que coleta os dados de diversas fontes, passando pela limpeza; ingestão; e o resultado, muitas vezes, é um repositório, Data Lake, com todos os dados necessários para a solução do problema e prontos para construir um modelo de machine learning.
Em sequência, o aprendizado de máquina é o núcleo central onde os dados limpos e no formato esperado são usados para treinar algoritmos em tarefas específicas.
Por fim, a etapa de DevOps, a parte interessada em operar o modelo criado em ambiente de produção e que possui uma camada de automação funcionando como uma esteira de testes unitários até o deploy.
DevOps não é o suficiente
O segundo princípio que gostaria de listar é que DevOps isn’t enough (DevOps não é o suficiente).
É importante explicar a diferença entre DevOps e MLOps. Muita gente se pergunta: mas eles não são a mesma coisa? Eles não estão resolvendo o mesmo problema?
A resposta é NÃO! O DevOps surgiu no auge do desenvolvimento de software para resolver o problema de implantar sistemas em produção que pessoas engenheiras de software e de infraestrutura sofriam.
Essa cultura nasceu para unir esses dois papéis que andavam distantes, a pessoa engenheira de software escrevia a aplicação e passava para a pessoa de infra subir em produção. O que ocorria era que esses sistemas demoravam muito para irem para a produção, por conta da falta de alinhamento entre as partes, e recorrentemente o código escrito por profissionais de engenharia de software voltavam centenas de vezes até estar no padrão ideal. O termo DevOps surgiu visando resolver esse problema.
Então, qual é a grande diferença entre DevOps e MLOps?
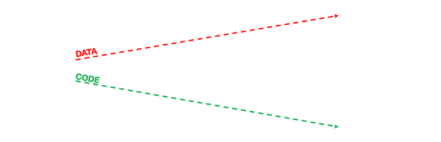
Quando estamos construindo um modelo de aprendizado de máquina, temos uma parte adicional que são os dados. DevOps foi um conceito para automatizar e evitar falhas de novos releases, além de melhorar a frequência de implantação em relação apenas ao CODE (um exemplo de CODE está relacionada com a imagem abaixo).
Você percebeu a diferença? O DevOps não visa lidar com dados, sejam eles internos ou externos aos scripts de código. Já em um ambiente de produção, nós temos uma dupla preocupação: código e dados.
Em DevOps
Em MLOps
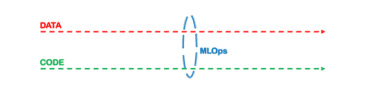
Então, o conceito de MLOps nasceu para resolver a forma como código e dados se relacionam, claro, herdando algumas boas práticas de DevOps (como automação, CI/CD, monitoramento de testes unitários etc.), mas com uma parte adicional que são os dados.
Em MLOps, temos o foco em fornecer sistemas baseados em dados de ML confiáveis e escaláveis, além de outras particularidades que nasceram nos MLOps que trataremos a seguir. Sem mais delongas, vamos pular para a arquitetura de ML.
Arquitetura de MLOps
Muito semelhante à arquitetura de software, que visa entregar sistemas em produção de forma escalável, mas aplicada para suportar sistemas de machine learning, não posso falar sobre arquitetura de ML sem citar um artigo popular feito pela equipe de engenharia do Google: MLOps: entrega contínua e pipelines de automação em aprendizado de máquina.
O artigo apresenta a arquitetura MLOps em três níveis diferentes. Inspirado por este artigo, fiz esta arquitetura baseada no mesmo, com ressalvas em partes da arquitetura, levando em conta minha experiência de trabalho sobre Arquiteturas de ML.
Também fiz um diagrama para mostrar visualmente e facilmente a arquitetura, incluindo os 5 blocos fundamentais de toda arquitetura de ML, garantindo confiabilidade mínima, escalabilidade e lançamentos rápidos.
Estes blocos são compostos por:
- Ingestão de Dados (Data Ingestion): onde podemos coletar dados para serem usados no modelo;
- Treinamento de Modelo (Model Training): que treina um modelo de aprendizado de máquina para resolver um problema de negócio;
- Registro de Modelo (Model Registry): uma vez que o modelo foi treinado, temos que manter seu artefato que é o modelo de machine learning salvo em disco;
- Avaliação de Modelo (Model Evaluation): para garantir que todas as métricas foram alcançadas neste modelo;
- Deploy (Model Serving): responsável pela implantação de um modelo a ser utilizado;
- Serviço de ML (ML Service): apenas uma ilustração do modelo colocado no aplicativo móvel, embutido no hardware, etc.
A seguir, vamos nos aprofundar nesses 5 blocos. Vamos lá?
Ingestão de dados
Disse anteriormente que a parte que muda o DevOps para se adaptar ao MLOps são os dados, um ingrediente fundamental no aprendizado de máquina.
Em um cenário real, temos Big Data como realidade, a quantidade e diversidade de dados que temos hoje no mundo é estrondosa e possibilita o avanço de modelos de machine learning mais sofisticados, permitindo solucionar problemas mais amplos com essa variedade de dados.
Essas informações chegam de várias fontes diferentes (tempo real, em processos de batch, banco de dados, etc.). É algo específico, principalmente, da empresa e do negócio.
Que tipo de dados você tem em suas mãos?
Fontes como bancos de dados, arquivos CSV, dados de aplicativos, etc. O ponto é como e onde você pode manter todos estes dados à disposição para serem criados novos produtos e serviços, não só nessa camada, mas em todas as outras da arquitetura presentes em serviços dos principais provedores de cloud (por exemplo, AWS, Google Cloud e Microsoft Azure).
Por estar fora do ambiente cloud, MLOps tem uma chance irreal de sucesso, praticamente zero, por isso, hoje o mundo se volta ao cloud computing.
Na camada de ingestão de dados, há anos uso o processo ETL para entregar dados em boa qualidade para estarem prontos para uso em treinamento de modelos.
Uma boa ferramenta que é muito usada em pipelines de dados é o Apache Airflow, que é responsável por gerenciar as etapas de limpeza até a entrega dos dados limpos, ingestão no data lake e habilitar o acesso desses dados em algum repositório.
No caso do data lake, temos muitas ferramentas para serem utilizadas, vou listar abaixo algumas das mais populares e, como mencionado anteriormente, focadas em ferramentas de nuvem.
Ferramentas Data Lake: AWS S3, AWS Lake Formation, GCP Cloud Storage.
Treinamento do Modelo
Chegamos na etapa de treinamento de modelo, onde vamos, de fato, selecionar uma amostra representativa dos nossos dados limpos e inserir no algoritmo de machine learning que escolhemos.
Todos os algoritmos de aprendizado de máquina usam dados como entrada para serem treinados e, assim, resolvem uma tarefa específica para a qual foram treinados.
Nos últimos anos, observamos grandes avanços nos algoritmos de aprendizado de máquina, arquiteturas maiores surgiram da pesquisa de IA, então, nos esforçamos consideravelmente em HPC (High-Performance Computing).
HPC é um termo recente e visa criar soluções de hardware eficientes e potentes o suficientes para suportar sistemas de software com uma alta performance, para sustentar todos esses novos modelos pesados. Por isso, o ponto de atenção está em torno da infraestrutura para suportar o treinamento do modelo.
No entanto, podemos treinar modelos hoje em CPU ou GPU. Treinar modelos em CPUs é um bom caminho se você possui conjunto de dados pequenos, onde o algoritmo de machine learning que você vai utilizar é simples no sentido de complexidade.
Já as GPUs são úteis quando se tem conjuntos de dados grandes. Para algoritmos mais sofisticados, por exemplo: redes convolucionais, arquitetura de transformers, redes generativas, etc., serão necessárias GPUs para solucionar o problema.
A diferença entre algoritmos de machine learning e deep learning, de forma resumida, é o tamanho do algoritmo em número de parâmetros e pesos. Algoritmos de deep learning tem um volume de parâmetros gigantesco, o que leva a mais tempo de treinamento.
Todas as ferramentas que listei abaixo suportam uma variedade de escalas que possivelmente você vai precisar!
Além disso, outra parte do treinamento do modelo é o conceito de CI/CD que significa Continuous Integration e Continuous Delivery (Integração Contínua e Entrega contínua), que podemos resumir como sendo dois processos que procuram revisar e garantir que o código que vai para a produção esteja nos padrões de qualidade que um sistema requer, que também é usado em MLOps.
Após treinar um modelo e antes de enviá-lo para a etapa de avaliação, precisamos verificar algumas partes do nosso código garantindo confiabilidade. Certo?
É importante dizer que estamos lidando com uma perspectiva de produção, onde o cuidado é rigoroso com o sistema que está sendo levado para produção e que vai ser consumido em larga escala.
A maioria das pessoas que considera treinar um modelo de aprendizado de máquina, tem preferência por criar seus modelos em notebooks jupyter, ferramenta usada amplamente para desenvolver modelos de machine learning.
Não quero questionar o uso de notebooks jupyter para treinar um modelo, mas no cenário de produção temos que converter esse código para scripts, onde podemos ter uma “confiança e segurança maior” a partir de testes unitários que serão feitos. Além de certificar se existe familiaridade com scripts de código, pois é essencial ter um bom conhecimento de engenharia de software e boas práticas, também é importante utilizar scripts para treinar modelos de larga escala.
Ferramentas de treinamento de modelos: AWS SageMaker, GCP Vertex AI, Kubeflow, Databricks.
Ferramentas de CI/CD: GitHub Actions, AWS CodeBuild, Jenkins, GCP Cloud Build.
Registro de Modelo
Uma vez que o modelo foi treinado, o próximo passo antes da avaliação é armazenar um artefato do modelo em algum lugar. Esta é uma prática bem conhecida em engenharia de software em relação ao armazenamento de artefatos produzidos por código.
Na adoção de MLOps, precisamos manter um artefato do modelo para ter um registro de rastreamento sobre ele, um verdadeiro histórico de versões.
Por exemplo, você está criando um modelo de aprendizado de máquina onde seu objetivo é fazer a detecção de fraude no contexto bancário. O comportamento da fraude é algo cíclico que se altera recorrentemente, ela é hoje de forma diferente da de amanhã.
Provavelmente, em breve, esse modelo precisa ser “retreinado” contemplando o “novo comportamento” da fraude que os dados evidenciam. Aliás, também surge a questão de criar um histórico de versões desse modelo, hiperparâmetros, dados que foram usados e assim por diante.
O registro de modelo nos permite comparar anteriores com novos. Analisando o desempenho e as métricas disponíveis para ajudar cientistas de dados a criar um modelo melhor do que o anterior. Ele é uma boa e confiável maneira de manter informações sobre o modelo de forma acessível e rápida.
Na minha experiência, acredito que a melhor ferramenta para o registro de modelos atualmente é o MLFlow, onde é possível gerenciar todos os ciclos de vida do modelo de aprendizado de máquina.
O MLFlow é composto por quatro componentes principais:
- Rastreamento que é utilizado para experimentos de registro e consulta;
- Projetos que são focados em código em um formato para reproduzir em qualquer plataforma (AWS, deploy on-premise etc.);
- Modelos focados em implantar modelos em diferentes ambientes (cloud, on-premise, serveless etc.);
- Registro focado em armazenar e gerenciar modelos em um repositório.
O MLFlow é um ótima ferramenta para se ter quando o assunto é ciclo de vida dos modelos. Além disso, é open source, possui suporte e ainda conta com um time engajado em evoluir a ferramenta.
Ferramentas de registro de modelo: MLFlow, registro de modelo do AWS SageMaker e registro de modelo Neptune.
Avaliação do modelo
Após o treinamento e a camada de registro do modelo, temos interesse em avaliar o modelo.
Em vários projetos em que trabalhei foi escolhida uma métrica de destino em um modelo para melhorar o máximo possível. Alguns casos podem ser a precisão, outros para melhorar a pontuação F1 e assim por diante.
A camada de avaliação do modelo tem a preocupação de validar se as métricas foram alcançadas ou não, portanto o modelo é avaliado em um conjunto separado de dados.
Em relação às ferramentas, podemos utilizar o AWS SageMaker, que possui recursos que permitem a avaliação de métricas, e o MLFlow como um complemento que pode ser usado para comparar métricas entre modelos.
É necessário validar se as métricas do modelo estão atingindo o esperado, caso não atinja o resultado, ele é re-treinado, seja com novos dados ou outras técnicas de modelagem sendo aplicadas. O importante é ter um ambiente que permita a validação de modelos em escala.
Ferramentas de Avaliação de Modelos: AWS SageMaker, MLFlow e Comet.
Deploy
A última camada é chamada de deploy, que é conhecida também como “serviço de modelo”.
Como mencionado anteriormente, a maioria dos projetos de ML falharam porque não lidaram e nem trataram um projeto de machine learning com uma abordagem de desenvolvimento de software.
Acompanhamos aqui todas as partes dos componentes e diversas ferramentas que hoje cumprem (e muito bem) o papel de fazer o deploy do modelo, permitindo disponibilizar ele em produção e que estará disponível para ser usado por outro software ou serviço independente.
O serviço de modelo tem que garantir testes de produção e releases de produção. Para isso, é necessário definir um método padrão para implantar.
Por exemplo, você pode implantar um modelo em tempo real entregando um endpoint de API, definir uma maneira padrão de colocar esse modelo na API ou se for necessário implantar um modelo em lote para mapear seus dados de saída, atividades como essa precisam ser definidas nesta camada.
Alguns testes que podemos usar para monitorar o modelo são: o tempo de latência do endpoint da API e quanto tempo a API recebe uma resposta ao aplicativo foi consumido.
No caso de implantar em lote, teste os dados de entrada e saída quando o lote estiver em execução. Além disso, verifique suas estatísticas: o desempenho e os resultados devem estar dentro do esperado.
Lembre-se, testes são cruciais antes de implantar modelos de aprendizado de máquina.
Ferramentas de deploy: AWS SageMaker Endpoints, Kubernetes, FastAPI, TensorFlow Serving, BentoML.
Conclusão
Uma vez que sua plataforma inicial de ML está pronta, temos um acompanhamento para melhorar e gerar o máximo de valor para a empresa.
A base para chegar até lá é feita, há pontos para serem trabalhados para melhorar a arquitetura de ML e seus serviços implantados, que está acontecendo com tempo e maturidade da equipe de MLOps,
Gostaria de dizer que esta arquitetura foi um fornecimento inicial pela minha experiência. No artigo escrito pelo Google há uma proposta de uma arquitetura nível 0 que não inclui nada sobre automação CI/CD, infrequente libera iterações.
Foi assim que o MLOps cresceu e nem tudo é regra de ouro. Por isso, propus esse artigo desta forma, como um passo acima do nível 0.
Quais são os próximos passos? O que falta de arquitetura?
Embora tenhamos uma base para melhorar a plataforma, os próximos passos envolvem olhar para os conceitos de CT/CM (treinamento contínuo e monitoramento contínuo) que nasceram em MLOps. Para isso, são necessários:
- modelos de aprendizado de máquina de retreinamento;
- mudanças na distribuição de dados ou diminuição do modelo de desempenho;
- e retreinar um modelo, o CM ajuda a monitorar a saúde do modelo em produção.
Espero que este artigo seja útil. Minha esperança é ver mais empresas fazendo MLOps por conta própria, construindo produtos e serviços mais confiáveis que beneficiem quem está ao seu redor.
Em breve, veremos grandes melhorias em ferramentas e boas práticas, acompanhe os últimos lançamentos em MLOps e nos vemos em breve!
Aproveite para continuar estudando no nosso blog! Temos vários conteúdos sobre tecnologia que você vai gostar de ler!



