Se você está ouvindo falar pela primeira vez em “modelo transformer” no contexto da computação pode estar se perguntando: será que tem alguma relação com o filme? ?
Pois bem, vamos lá… segundo a wikipédia, os transformers dos filmes são robôs alienígenas fictícios de uma franquia popular da Hasbro, capazes de transformar seus corpos em objetos inócuos como veículos.
Sendo assim, posso dizer que não é exatamente sobre isso que iremos tratar nesta postagem, mas se pudesse destacar uma característica em comum entre o modelo transformer que iremos apresentar aqui e os robozões dos filmes é que ambos são bem poderosos.
Só que no caso dos modelos, eles não são fictícios e podem ser úteis para várias atividades inteligentes no seu dia a dia.

Texto alternativo:
Neste artigo, vamos conversar um pouco sobre o que é um modelo transformer no contexto de deep learning, destacando características, aplicações, estratégias de uso e finalizando com uma implementação de um exemplo prático de uso.
O que é um transformer?
Os conceitos para o entendimento do que é e de como funciona um modelo transformer possivelmente exigirão algumas leituras complementares que irei deixar ao longo do texto.
Por isso, aqui quero apresentar uma introdução deste entendimento, desde uma contextualização até uma abordagem prática com uma implementação de uma pesquisa semântica em Python.
De forma direta, definiria um transformer como um modelo de deep learning dotado de mecanismos de autoatenção. Esses mecanismos possibilitam a aprendizagem de contextos (por exemplo, linguístico para o Processamento de Linguagem Natural – PLN), mesmo em elementos que possuem dados distantes, como ocorre em dados sequenciais, possibilitando uma análise semântica de palavras em uma frase.
Vamos puxar um pouco do cenário histórico para explicar o motivo do uso do transformer ser tão legal.
Redes neurais
Antes da popularização do uso de estratégias de implementação com o modelo transformer, as pessoas precisavam treinar redes neurais com grandes conjuntos de dados rotulados. Esses processos de treinamento normalmente eram demorados e caros em investimento e capacidade de processamento.
As camadas de autoatenção do transformer eliminam a necessidade de rótulos para a identificação de padrões, o que abre um leque para várias possibilidades de treinamento de novos dados e de maximizar a performance para a execução dos modelos.
Redes neurais clássicas não foram projetadas para um bom desempenho em acompanhar dados sequenciais e mapear cada entrada em uma saída. Isso pode até funcionar bem para atividades de classificação de imagens, mas falha em dados sequenciais, como em textos.
Dessa forma, um modelo que visa o processamento de textos deve levar em consideração como as palavras vêm em sequência e se relacionam umas com as outras. O significado das palavras pode mudar dependendo de outras palavras que vêm antes e/ou depois delas na frase.
As redes neurais recorrentes (RNN) eram a solução para estes cenários de processamento de linguagem natural (PLN). Quando fornecida com uma sequência de palavras, uma RNN é capaz de processar a primeira palavra e realimenta o resultado na camada que processa a próxima palavra.
Isso permite que ele acompanhe a frase inteira em vez de processar cada palavra separadamente. Porém, essa abordagem é lenta, não consegue lidar com sequências longas de textos e captura apenas as relações entre uma palavra e aquelas que vieram antes dela, não as que vêm depois.
Um avanço da RNN foram as redes de memória de longo prazo (LSTM), capazes de resolver o problema dos gradientes de fuga até certo ponto e de lidar com sequências maiores de texto. Porém, eram ainda mais lentas para treinar do que as RNNs.
Uma solução
O modelo transformer foi apresentado em 2017 no artigo “Attention is All You Need”, fazendo contribuições claras para o cenário de PLN e abrindo importantes possibilidades de seu uso em outros contextos.
O transformer possibilita o processamento de sequências inteiras em paralelo, possibilitando escalar a velocidade e a capacidade de modelos sequenciais. Além disso, eles introduziram o conceito de “mecanismos de autoatenção”, que possibilitam rastrear as relações entre palavras em sequências de textos muito longos nas direções direta e reversa.
Como um modelo transformer presta atenção?
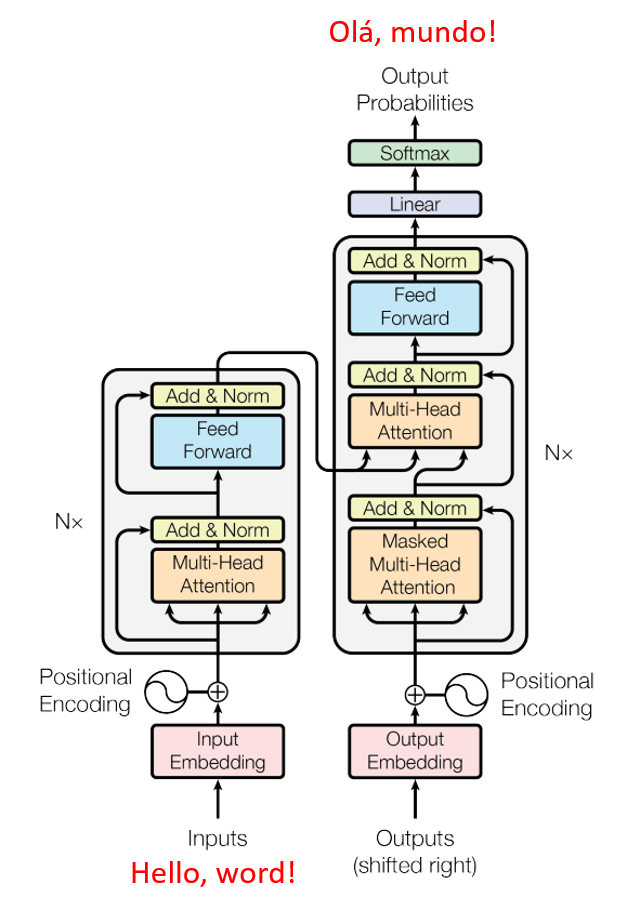
Como ocorre na maioria das redes neurais, os modelos transformers atuam basicamente como grandes blocos que processam e transformam dados em atividades de encoder (codificação) e decoder (decodificação). Mas, em especial, o transformer consegue codificar dados sequenciais, como textos, de forma posicional, marcando os elementos e fornecendo um contexto.
As unidades de atenção seguem estas marcações calculando como cada elemento se relaciona com os demais. As consultas de atenção podem ocorrer de forma paralela, permitindo que computadores possam analisar padrões que antes só eram detectados por seres humanos.
- O encoder (codificador) recebe e processa uma entrada para a geração de informações sobre quais partes desta entrada são relevantes umas com as outras. O modelo é otimizado para obter o melhor entendimento da entrada.
- O decoder (decodificador) gera uma sequência alvo usando a representação do codificador e as informações contextuais para gerar as saídas.
A camada de autoatenção diz para o modelo quais elementos ele deve prestar atenção a detalhes frente ao contexto de análise específico.
Na prática
Um exemplo deste processo pode ser ilustrado em uma atividade de tradução.
Nesse caso, um transformer recebe um corpus linguístico de frases em inglês e suas respectivas traduções em português. O encoder recebe e processa uma palavra(string) de entrada completa. O decoder, no entanto, recebe uma versão mascarada da string de saída, uma palavra por vez, e tenta estabelecer os mapeamentos entre o vetor de atenção codificado e o resultado esperado.
O encoder tenta prever a próxima palavra e faz correções com base na diferença entre sua saída e o resultado esperado. Esse feedback permite que o transformer modifique os parâmetros do encoder e do decoder, criando gradualmente os mapeamentos corretos entre os idiomas de entrada e saída, gerando um mecanismo de tradução eficiente.
Quanto mais dados e parâmetros de treinamento o transformer tiver, mais capacidade ele ganhará para manter a coerência e a consistência em longas sequências de texto. A figura a seguir ilustra este processo:
Onde modelos transformers podem ser utilizados?
Nos últimos anos, o modelo transformer se tornou um dos principais destaques da área de deep learning.
Para quem já assistiu a algum filme dos Transformers (aquele dos robôs alienígenas), sabe que o Bumblebee é um robô que não consegue falar e se comunica através de estações de rádio. Pois bem, os modelos transformers em deep learning que estamos conversando até aqui são muito bons em atividades avançadas de processamento de linguagem natural, como Bumblebee, e também podem salvar sua vida em algumas situações.

Além da área de PLN, desde seu lançamento em 2017, o uso de transformers se expandiu para diversas tarefas como a previsão de séries temporais, sistemas de detecção de fraudes, sistemas de recomendação, modelos de geração de código-fonte no OpenAI e, mais recentemente, chegaram à visão computacional.
Inclusive, você possivelmente já usou algum modelo transformer ao fazer alguma busca no Google, a empresa usa essa estratégia para melhorar seus resultados de busca.
Se você precisa analisar dados sequenciais de textos, imagens ou vídeos, muito provavelmente o uso de modelos transformers serão fortes candidatos para você considerar. Mais alguns exemplos de uso por áreas:
- ? Texto: classificação de texto, extração de informações, resposta a perguntas, resumo, tradução e geração de texto em mais de 100 idiomas.
- ?️ Imagens: classificação de imagens, detecção de objetos e segmentação.
- ?️ Áudio: reconhecimento de fala e classificação de áudio.
- ? Multimodal: reconhecimento óptico de caracteres, extração de informações de documentos digitalizados, classificação de vídeo e resposta visual de perguntas.
Modelos pré-treinados
Modelos transformers podem ser complexos e custosos para serem desenvolvidos e treinados do zero. Alguns deles, podem exigir ajustes finos e foram treinados por dezenas de bilhões de parâmetros. Caso você queira economizar tempo no treinamento do seu modelo, você pode dar uma olhada na biblioteca de transformers no Hugging Face.
Ela é formada por diferentes modelos transformers já pré-treinados para a realização de diferentes tarefas e é acessível por meio de APIs de alto nível. Os modelos podem ser carregados, treinados e salvos sem problemas.
Vamos construir um exemplo prático de uso de transformer?
Para ilustrar o uso de modelos transformers, apresentamos um exemplo de implementação do Sentence Transformer para a criação de pesquisas semânticas com base no modelo pré-treinado BERT.
Aqui você pode acompanhar a implementação!
Conclusões e o que vamos fazer daqui para frente
Vimos o impacto que soluções baseadas em modelos transformers podem trazer no dia a dia das pessoas. Além disso, profissionais de pesquisa ainda estão explorando maneiras de melhorar ainda mais os transformers e usá-los em novas aplicações.
Aqui na Zup, estamos utilizando o modelo transformer para estratégias de correções e avaliações automáticas de códigos-fonte.
Utilizamos o modelo transformer para cálculos de similaridade semântica entre dois códigos. Esse cálculo de similaridade pontua a relação entre um código de referência (bom código) e uma implementação a ser avaliada.
Foi definida a métrica de similaridade de cosseno para comparação entre os códigos, que após ser calculada, é normalizada frente a atribuição de uma nota, de 0 a 10, a depender do quão próximo o código a ser avaliado está do código de referência.
Se interessou sobre esse tema? Temos uma postagem aqui no blog sobre Processos de Code Review com Inteligência Artificial que pode lhe interessar.
Existem vários desafios ainda abertos nesta área de pesquisa e pretendemos manter a comunidade informada quanto aos nossos avanços por aqui!
Ficou com alguma dúvida? Tem alguma sugestão? Quer falar com a gente? É só me procurar no Linkedin ou enviar seu comentário aqui abaixo ?.