

Os testes de software com IA (Inteligência Artificial) são uma alternativa automatizada que pretende trazer grandes benefícios para a rotina de devs.
Neste artigo, vamos apresentar as abordagens, principais características e ferramentas desses testes, além de refletir sobre qual será a sua utilidade no cotidiano do desenvolvimento de software.
Por que escrever testes de software?
A vida atual é cercada de softwares. Diversas atividades do dia a dia são mais rápidas e eficientes graças às inovações trazidas pelo uso de softwares, como transporte, telecomunicações, viagem, lazer, finanças e muitas outras.
Uma triste consequência dessa nova realidade é o aumento da complexidade no desenvolvimento, o que torna os softwares sujeitos a todo tipo de erro e inconsistência.
É essencial evitar que esses erros sejam propagados e cheguem a pessoas usuárias finais, o que pode causar prejuízos incalculáveis a negócios, pessoas e até mesmo a sociedade.

Dessa forma, testar o software antes que entre em produção aumenta a qualidade e a segurança do que será entregue, além de diminuir os custos de desenvolvimento por antecipar a detecção dos erros.
Testes manuais e automatizados
Há diversos tipos de testes de software, que podem ser executados manualmente ou automaticamente. Os testes manuais dependem 100% da interação humana, o que torna testar uma atividade de grande esforço, lenta, monótona e com grande chances de não detectar erros.
Os testes automatizados, por outro lado, minimizam o esforço humano através da criação de um conjunto de testes que são executados com o auxílio de ferramentas especializadas.
Porém, cada alteração no software necessita ser refletida nos testes, ou seja, é necessário que esse conjunto de testes seja mantido atualizado para as mudanças no código, sempre verificando se o software continuará de acordo com as especificações e objetivos desejados.
Estudos indicam que pessoas desenvolvedoras não costumam implementar e executar testes ou realizam essa atividade de forma superficial. É nesse ponto que a Inteligência Artificial (IA) pode entrar e mudar o cenário.
Testes de software com IA
Com os métodos ágeis, os testes passaram de uma das últimas fases executadas no desenvolvimento de um software para uma fase contínua, onde se deve implementar os códigos e os testes em simultâneo. Porém, o número de testes para um software pode ser gigantesco. Além disso, garantir que um software está livre de bugs é impossível (logo, não há quantidade exata de testes necessários para livrar um software de bugs).
Diante disso, uma questão que surge é: como realizar essas atividades de implementação de classes e testes com agilidade, eficiência e qualidade? A resposta é o uso de IA.
Com IA, é possível gerar testes de forma rápida, que cubram mais partes do software e em menos tempo. Dessa forma, os times de desenvolvimento e teste podem focar em atividades menos monótonas, concentrando o esforço humano em atividades mais produtivas, o que culmina no aumento da confiabilidade do software ao permitir melhorias contínuas na qualidade.
Abordagens de IA
A seguir, vamos conhecer um pouco mais sobre as abordagens mais famosas de IA para a criação de testes de software automatizados. Focamos somente em estratégias para a criação de testes de unidade, visto que esse tipo de teste é o mais comum.
1- Busca aleatória dirigida por feedback
Uma das abordagens mais simples para a solução de qualquer problema em IA é a busca aleatória de uma resposta satisfatória entre todas as respostas possíveis (válidas ou não).
É como procurar algo no escuro: você busca em todos os locais possíveis sem saber se já visitou aquele lugar, ou se está perto, ou longe do local onde está o que precisa.
Naturalmente, esse tipo de estratégia também pode ser utilizada para a geração de testes, porém o número de respostas possíveis pode ser infinito, o que torna a busca extremamente lenta ou impossível de ser completada. De fato, acredita-se que casos interessantes de testes tem uma chance baixíssima de serem criados aleatoriamente.
Assim, é necessário uma heurística (ou seja, uma “linha de raciocínio”) que priorize escolhas que pareçam levar para o que se deseja no menor número de passos possíveis.
Em geração de testes, a técnica mais famosa desse tipo se chama aleatório por feedback (Feedback-directed random). A ideia dessa técnica é construir um teste de forma iterativa, estendendo um teste anterior que obteve sucesso com chamadas para métodos ou construtores escolhidos aleatoriamente. O teste vai sendo estendido até que se produza uma violação do tempo de execução (o que pode ser evidência de um erro).
Um exemplo, possivelmente o mais conhecido, dessa abordagem é a ferramenta RANDOOP.
Embora utilize uma abordagem simples, RANDOOP já revelou erros anteriormente desconhecidos em ferramentas amplamente utilizadas, como em JDKs da Sun e da IBM. Além disso, o RANDOOP é usado até hoje em aplicações industriais e segue sendo mantido para projetos Java e .NET.
2- Execução Simbólica
Execução simbólica é uma técnica de análise de software que examina se, seguindo os caminhos possíveis de execução, certas propriedades podem ser violadas (por exemplo, se uma divisão por zero será realizada).
Por exemplo, quando se testa um software manualmente, seleciona-se um conjunto de entradas de forma arbitrária (por exemplo, entrada nula, valores numéricos aleatórios) e segue-se um caminho de execução por vez, resultando em saídas relacionadas àquelas entradas.
Diferentemente, na execução simbólica executa-se o software de forma abstrata, cobrindo vários caminhos de execução de uma única vez.
É semelhante a construir uma árvore binária de caminhos de execução, onde cada nó da árvore representa um ponto de decisão (por exemplo, um “if/else”, atribuição de valor para uma variável, etc.) e cada aresta representa as opções possíveis para aquele ponto de decisão (e.g., falso ou verdadeiro, maior ou menor que zero, etc.), como vemos na imagem abaixo, do Research Topics in Software Quality.

Note que embora a ideia geral lembre um pouco a abordagem anterior, aqui os caminhos são concretos da execução do software (isto é, embora use valores abstratos, não são valores aleatórios, os quais podem nem ser verdadeiros!).
Isso evita avisos falsos, pois cada erro encontrado na execução simbólica representa um caminho factível da execução do software. Se o caminho termina devido a um erro, é possível construir casos de teste ao seguir aquele caminho com valores concretos. Além disso, caminhos de execuções mais complexos podem ser examinados com execução simbólica, os quais podem nem ser encontrados pela busca aleatória.
Concolic: execução simbólica e concreta
Claramente, gerar todos os caminhos de execução possíveis é inviável na prática. Por exemplo, no caso de laços, pode-se ter infinitos caminhos, causando uma explosão de recursos. Assim, a execução simbólica moderna mistura execução simbólica e concreta, o que é chamado de concolic (“conc” de concrete e “olic” de symbolic). Essa abordagem pode ser descrita nos seguintes passos:
- Escolhe-se valores arbitrários para execuções concretas;
- Executa-se o software de forma concreta (com valores para as entradas) e simbólica (valores abstratos);
- Ao criar um novo caminho de execução através da execução concreta, a execução simbólica é guiada para o mesmo caminho.
Ou seja, na execução concolic, a execução simbólica é guiada pela execução concreta. Com isso, a execução simbólica é simplificada, o que pode acelerar o processo de geração de casos de teste. Porém, a quantidade de caminhos de execução encontrados ainda pode ser um desafio, o que exige o uso de heurísticas para a reduzir a quantidade de caminhos explorados.
Existem diversas ferramentas que utilizam execução simbólica para geração de testes, sendo possivelmente a abordagem mais antiga e mais famosa nessa área. Caso tenha curiosidade, você pode encontrar uma lista extensa para diversas linguagens no GitHub.
3- Algoritmos Evolucionários
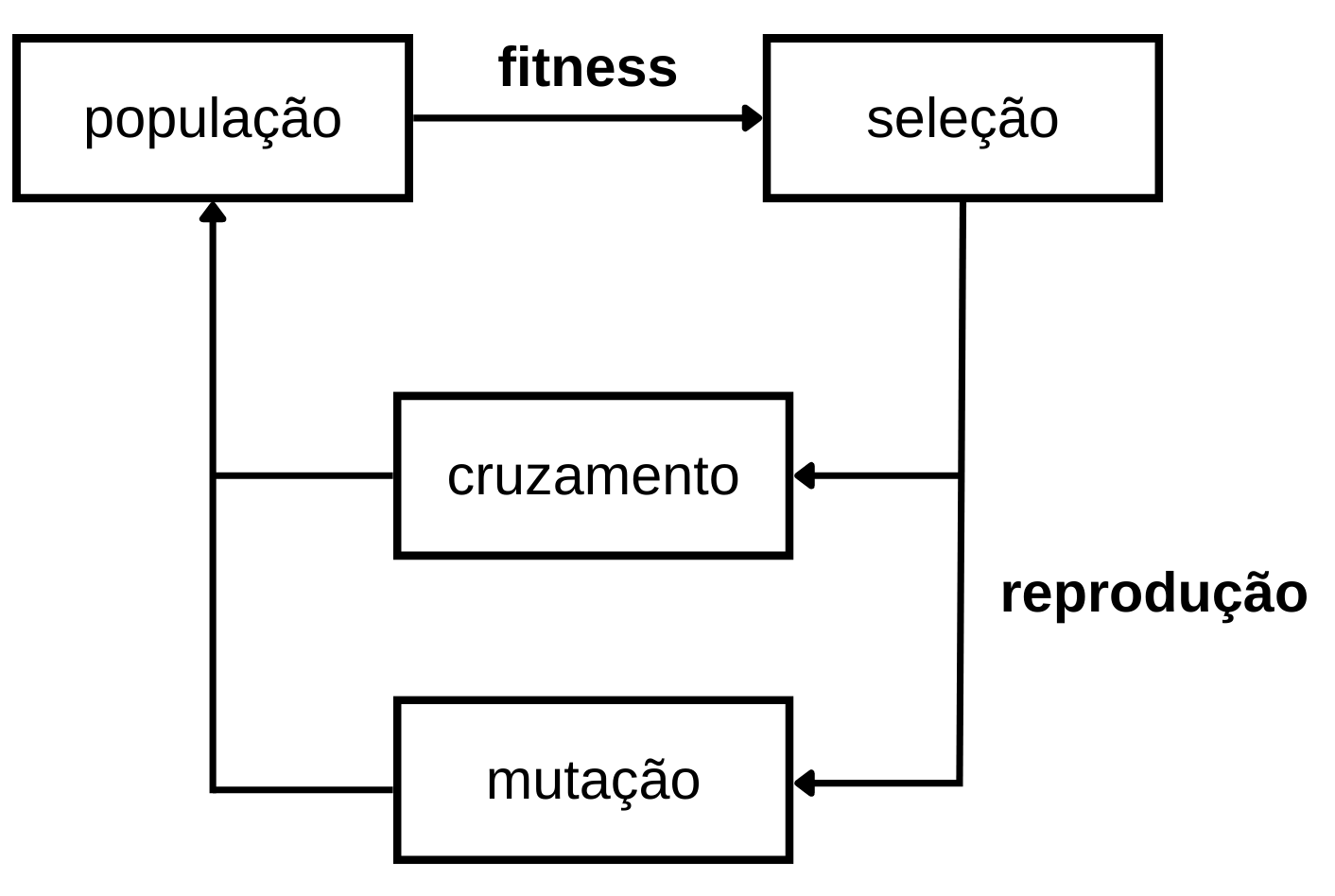
Algoritmos evolucionários (AE) são baseados no processo natural da evolução biológica descrita por Darwin, seguindo os mecanismos associados, como seleção, reprodução e mutação. Além disso, são técnicas ideais para problemas semelhantes a geração de casos de testes: complexos e dinâmicos, sem garantias de uma solução ótima.
No contexto de AE, o algoritmo mais clássico e mais utilizado em diversas aplicações se chama Algoritmo Genético (AG), que é simples de entender e implementar, além de obter bons resultados. O processo do AG pode ser descrito como:
- Uma solução é codificada geneticamente como um indivíduo (os cromossomos que carregam informações hereditárias de um organismo). Um conjunto de indivíduos forma uma população e essa população vai sendo gradualmente evoluída ao longo das gerações através da seleção natural;
- Para determinar o grau de adaptabilidade de um indivíduo (isto é, determinar se esse indivíduo tem chances de sobreviver, seguindo o ciclo da seleção natural), calcula-se sua fitness, que é uma métrica (ou várias métricas combinadas como uma) que mede o quão apto o indivíduo está para sobreviver naquele sistema;
- As formas mais comuns de ocorrer a seleção natural é classificar os indivíduos e escolher os mais adaptados (ranking) ou colocá-los num torneio (semelhante a uma batalha Pokémon): sorteia-se alguns indivíduos e aí seleciona-se os mais adaptados (melhor fitness) de cada torneio;
- Os selecionados são cruzados (trocam material genético). Também pode ocorrer uma mutação genética, onde um indivíduo tem pequenas chances de sofrer uma alteração genética aleatória.
Esse processo é repetido até atingir um critério de parada (por exemplo, valor da função de fitness do melhor indivíduo abaixo de um threshold ou número máximo de gerações, onde uma geração é cada repetição desse processo).
Traduzindo todo esse processo em termos de testes:
- Cada indivíduo é um conjunto de testes de tamanho aleatório. Esses testes são formados de definições de variáveis primitivas, chamadas para construtores ou chamadas de métodos.
- A seleção natural pode ser por classificação ou torneio.
- O cruzamento é baseado na troca de testes entre os conjuntos.
- A mutação adiciona/remove testes dos conjuntos e também adiciona/remove/modifica o conteúdo de um teste (sendo necessário verificar se com essas alterações o teste continua válido).
Nesse processo, a fitness é um conjunto de objetivos (por exemplo, cobertura por linhas, por branch, etc.). Há modificações que permitem utilizar diversas fitness de forma separada, o que inclusive permite que cada indivíduo passe a ser um único conjunto de testes.
Essas e várias outras modificações (e também a implementação clássica) do AG podem ser encontradas, por exemplo, na EvoSuite (para Java) e também na Pyguin (para Python).
4- Grandes Modelos de Linguagem
O desenvolvimento tecnológico trouxe uma quantidade massiva de dados ao mundo, não só dados estruturados (como tabelas), mas também desestruturados (como, imagens, sons e textos).
Além disso, houve um aprimoramento do poder computacional; por exemplo, a capacidade de processamento e memória das GPUs cresceu 10 vezes nos últimos quatro anos. O Aprendizado de Máquina (Machine Learning – ML) se beneficiou e muito dessas transformações através do Aprendizado Profundo (Deep Learning – DL), que vem inovando intensamente a forma como vemos o mundo.
Porém, as primeiras redes neurais profundas voltadas para o aprendizado em sequências longas (por exemplo, textos e códigos) processavam suas entradas de forma sequencial. Com isso, quanto maior a sequência, maior precisava ser o modelo da rede neural (e, consequentemente, mais tempo e poder computacional eram necessários para que esses modelos aprendessem).
Mais ainda, sequências maiores tornavam o aprendizado mais complexo, pois essas redes neurais têm mais dificuldade em relacionar as partes (digamos que elas esquecem parte das sequências). Com a chegada dos modelos Transformers, foi possível paralelizar o processamento das sequências de longo prazo, o que aumenta a capacidade de aprendizado e a velocidade com que esse aprendizado é realizado.
Tudo isso culminou nos Grandes Modelos de Linguagem (Large Language Models – LLM), que são modelos transformers gigantes que aprendem com uma quantidade massiva de dados.
Assim, ao aprender a partir de uma quantidade enorme de informações, esses modelos se tornam capazes de entender mais padrões de linguagem, atingindo resultados incríveis mesmo em atividades às quais não foram designados previamente para realizar, tendo pouca ou nenhuma informação sobre essas tarefas.
É essa capacidade extraordinária de generalizar informações que torna LLM aplicável para atividades de geração de código. Por exemplo, há vários modelos voltados para a transformação de linguagem natural em código (como esse A Generative Model for Code Infilling and Synthesis).
Isto é, você diz ao modelo o que deseja e ele retorna um código para aquela tarefa. É possível gerar softwares inteiros, traduzir de uma linguagem para outra… o céu é o limite.
Sem dúvidas, gerar testes também é possível com LLMs, como nestes dois exemplos: Code Generation with Generated Tests e Generating accurate assert statements for unit test cases using pretrained transformers.
Caso de teste
Para ilustrar, temos a imagem abaixo retirada do primeiro exemplo, onde é gerado um caso de teste e o código para a tarefa desejada a partir da descrição (em inglês).
Nesse exemplo, a intenção é construir uma função que verifique em uma lista de números se quaisquer dois números estão próximos, dado um threshold (ou seja, se n1 – n2 < threshold).
Para construir o teste, deve-se simplesmente adicionar um comentário pedindo para verificar a corretude da função que se deseja. Com isso, o modelo gera o teste e o código que realiza a atividade de interesse, testando esse código com os testes que ele mesmo gerou. Bacana, né?

Como podemos utilizar estas abordagens na Zup?
A comunidade de testes de todo o mundo está otimista e com altas expectativas para o uso de IA nessa área, o que está mudando aos poucos as rotinas de teste automatizados, especialmente:
- no desenvolvimento e manutenção dos softwares;
- reduzindo o tempo de maturidade das ferramentas;
- consequentemente, acelerando o deployment dos produtos.
Como não podia ser diferente, nós da Zup queremos que cada pessoa desenvolvedora #ResolvaOProblemaCerto. Por isso, na Zup Edu, estudamos e propomos diversas maneiras de facilitar o dia a dia dessas pessoas, tornando-as cada vez mais capazes de atuar no contexto necessário.
Assim, nossa dedicação inicial é explorar e implementar modelos baseados nas técnicas de IA descritas neste artigo para geração de testes em Java. Naturalmente, diversas questões surgem nesse contexto e guiam a nossa exploração, por exemplo:
- Os testes criados através de técnicas de IA são mais efetivos que os testes manuais?
- Quais as vantagens e desvantagens do uso desses métodos?
- É possível determinar os contextos no qual uma técnica (ou ferramenta) é melhor que outra?
Nossa intenção é encontrar as respostas para essas e muitas outras questões, trazendo resultados positivos e avanços para a vida das pessoas desenvolvedoras. ?
Conclusão
Como muitas pessoas desenvolvedoras realizam a implementação de testes de forma superficial ou até mesmo não a realizam, surgiu a oportunidade de realizar esses testes com rapidez e eficiência com a Inteligência Artificial.
Neste artigo, apresentamos estratégias para a criação de testes de unidade: busca aleatória, execução simbólica, algoritmos evolucionários e grandes modelos de linguagem.
Os testes de software com IA ainda são um campo coberto de expectativas. Incentivamos que devs mergulhem nessas técnicas que surgiram para otimizar os seus trabalhos e entregar resultados cada vez mais sofisticados.
E aí, o que achou de gerar testes com o auxílio de IA? Tem outras dúvidas ou sugestões? Conte para a gente nos comentários!



